Automatic removal of junk instructions through state tracking
published 2018-05-18
Abstract
There are a lot of methods to obfuscate code but they all share the objective of making the code less readable in order to thwart reverse engineering. One common method is inserting junk instructions to blow up code size making it hard to distinguish between meaningful instructions and code that effectively does nothing.
I propose a solution to automatically filter out junk instructions by tracking the execution state. Using Triton we statically analyze a code trace over obfuscated code and keep track of which instruction has which side effect (for example register and stack writes).
At an arbitrary stopping point, we can then use this information to recursively scan backwards for instructions responsible for state changes and mark them as good, or meaningful. This automatically excludes junk instructions as they ought to not make meaningful state changes by definition.
I have implemented a proof-of-concept script in Python that can be run in IDA Pro and statically remove junk instructions given an entry point. It is only about 200 lines of code.
Introduction
I have been looking for an excuse to play around with obfuscated/virtualized code for a while. Recently I found a malware sample that was heavily obfuscated making reading the code almost impossible. Reports identified the sample to be packed with VMProtect, a commercial virtualization packer. Looking at it in IDA revealed that not only does it use virtualization but also heavily obfuscates the code by inserting junk instructions.
My goal then was to see if I can statically remove those junk instructions in order to be able to just read the code. I did a quick Google search for automatic junk instruction removal but did not find anything really. As I wanted to try myself at the problem anyway, I stopped searching for prior research. It is therefore possible that my approach has been done before and I have just reinveted the wheel. I'd be happy to read about how others solved the problem!
When I first set out to solve the problem, I meant to document the journey of solving the problem because I myself like to read about those the most but quickly noticed it is very hard to document the whole process with all the trials and errors and the thought process behind them. Reverse engineering is just an inherently non-linear process and as such that did not work.
I still hope the article is interesting enough in itself while describing only what worked eventually.
What are junk instructions

If we want to remove junk instructions, the first question to answer is what a junk instruction even is.
Some obvious examples:
lea eax, dword ptr [esp]
mov eax, 7
The lea is junk as it writes eax which is overwritten in the very next instruction.
Or using the flags:
clc
add eax, num
The clc (clear carry flag) is junk because add sets the carry flag.
In general I decided on the following definition:
A junk instruction is an instruction for which no other instruction cares
about its side effects
Basically, an instruction that writes a register, or a flag, or the stack, or the memory but nobody ever reads that value. Above examples are just that, they have a side effect (written register and written CF) but nobody cares about them before they are overwritten.
Boundaries
A very practical question I had to answer first is: Where do I start my automated code analysis, and where do I end? What are the boundaries of code I analyze in order to remove junk instructions.
In the previous section, you may have noticed the emphasis on ever. That is an actual, hard problem, because we need to start and end our analysis for junk instructions somewhere.
In order to dismiss an instruction, we must be certain that no single instruction in the whole code ever cares about any side effects it has. But that would require perfect knowledge of the whole program and I'm sure this sooner or later fails on the halting problem because everything does. In any case, it's commonly known that for computers based on the Von Neumann architecture this is a hard problem.
For very simple programs (think no conditionals, just one basic block) we can easily gain total knowledge of it, but what about a programm where some register is written and only a conditional block inside an if later on accesses it. Or worse, some conditonal block inside a loop only after the 1000th iteration accesses it. We would need to explore every possible code path and that would explode in our face. I looked into algorithms to find every trace through loops without repeating blocks, which exist but even for simple loops the number of pathes simply exploded.
So if we can't satisfy the ever requirement, what do we do?
This puzzled me a while when I had kind of an epiphany. The trick is thinking about how a code obfuscator knows where to insert junk instructions. Because in order to not change code semantics, the obfuscator itself must be sure that whatever side effects the junk instruction has doesn't matter. So if they want to insert a clc, they must be sure nothing ever relies on the carry flag afterwards, until some of the original code writes it.
So effectively, they have to solve the very same problem, requiring perfect knowledge, if they want a general solution!
Which is why I assumed they just narrowed the problem down to something like:
We only insert junk instructions before other writing instructions, thus
making sure their side effects are meaningless
Basically, they just do dead stores as the examples above.
The question still standing is, where do we stop to deobfuscate code? The starting point shall be arbitrary for whatever the reverser thinks looks interesting. We also cannot analyze the whole program. Assuming the dead store hypothesis holds, we could stop at any writing instruction and start finding junk instructions. That would leave junk instructions for which a write happens afterwards.
I chose a different approach. The start for the analysis is arbitrary, and so is the end. I then assume any written register, memory, stack location at that point in time is relevant. In hindsight that is obvious. It will give us on overapproximation because there may be someone overwriting current state later on but that is fine.
So that was a lot of text for "where do we start, where do we end" - wherever.
The algorithm
The final algorithm I chose works like this:
- At some arbitrary point we start tracing
- For every instruction encountered, we track state changes. We save a structure together with every instruction that records what state variable was last written by which instruction, which include side effects the current instruction itself has.
- At some arbitrary point we stop tracing and declare everything in the state structure meaningful or relevant.
After the trace we have to work backwards.
- The state structure of the last instruction holds every state variable and who wrote to it. We mark every instruction recorded inside as meaningful.
- For each meaningful instruction, we query what the instruction reads (e.g. what register it reads, or memory location). We then look up the instruction who last wrote to that state variable and also mark them meaningful as a meaningful instruction depends on them.
- Repeat until no more instructions are implicitly meaningful.
An example probably explains it best.
Here is our made-up obfuscated code:
1 mov eax, 1337
2 mov ecx, eax
3 add ecx, edx
4 mov edi, 42
5 mov ebp, 3
6 lea ebp, dword ptr [eax+3]
7 xor ebp, ebp
We trace over each instruction recording state changes. The state initially is empty, and inside the state we record the instruction who wrote it.
# Instruction State after instruction
0 initial empty
1 mov eax, 1337 eax:1
2 mov ecx, eax eax:1, ecx:2
3 add ecx, edx eax:1, ecx:3
4 mov edi, 42 eax:1, ecx:3, edi:4
5 mov ebp, 3 eax:1, ecx:3, edi:4, ebp:5
6 lea ebp, dword ptr [eax+3] eax:1, ecx:3, edi:4, ebp:6
7 xor ebp, ebp eax:1, ecx:3, edi:4, ebp:7
Now we check the last state and mark every instruction inside good, which would be instructions (1,3,4,7). Then we walk over the list of good instructions and see what they depend on.
- Instruction 1 depends on nothing, done
- Instruction 3 depends on
ecxandedx. Foredxwe have no information, but forecxwe look up who wrote to it in the previous' instructions state and find thatecxwas written by 2. Add 2 to the good list. - Instruction 4 depends on nothing, done
- Instruction 7 depends on nothing, done
This iteration added 2 to the good list, so we check 2 again:
- Instruction 2 reads
eax, we look up in the previous' instruction state who wrote it and find 1. Instruction 1 is already in the good list, and the algorithm is done.
The final list of meaningful instructions is (1,2,3,4,7), instruction 5 and 6 got implicitly discared because nobody cared about their side effect and we have our deobfuscated code:
1 mov eax, 1337
2 mov ecx, eax
3 add ecx, edx
4 mov edi, 42
7 xor ebp, ebp
We of course do not know if anyone ever cares about edi being 42, or ebp being 0, but at this point in time, the instruction 4 and 7 are responsible for their value and as such cannot be discarded safely.
Complications
Of course it is not that easy (but at least close). In practice a bunch of things complicate the process.
Problem 1 - Register aliasing
Example:
mov eax, 0xFFFFFFFF
mov ax, 1337
Both instructions are meaningful. The 2nd one partially overwrites eax, but the upper 16 bit still depend on the first one. Luckily I didn't find any code in my VMProtected binary that does this. Therefore, I was lazy and simply converted each register to its largest form before recording writes. VMProtect does use a lot of di, ax, bh and so on but does never seem to alias them, so that works.
Problem 2 - What do we consider state?
This was a bit more difficult. Regarding every register for example as relevant does not work. If we consider eip relevant at all, every instruction will be marked meaningful as every instruction obviously modifies eip. I therefore excluded eip.
I also excluded memory writes for now but that should be a straight-forward fix.
But what about esp. Obviously stack writes are quite relevant but what about changes to esp itself?
Problem 3 - The stack
This also is not that easy. VMProtect likes to use junk instructions that write to the stack and then later discards the values without using them.
Example:
pushad
lea esp, dword ptr [esp+xxx]
When I tried to consider esp as relevant and tracked it, a lot of stack junk instructions kept being included so I decided on the following approach:
espis completely excluded from state tracking- Stack writes are tracked just as register writes by their address
- Before adding an instruction to the list of instructions, I discard every stack write in the state, if
espis above it.
This means that the above example is handled like this:
Instruction State
pushad stack0:1, stack1:1, stack2:1 ... stack7:1
lea esp, dword ptr [esp+40] empty
pushad writes to 8 memory locations on the stack and we track them just like registers. lea then modifies esp and moves it up 40 bytes. Now esp is above all the previously written stack locations and are therefore removed from the state. As a result, the pushad is considered junk.
This worked surprisingly well and had no issue with ignoring junk instructions that affect the stack.
The tool
Finally, I'll talk about my code. From the start I wanted to have a static tool I could run in IDA that gives me readable code. I use Triton, a dynamic binary analysis framework to do the static code tracing. It also provides all the information I need, such as read/written registers, memory locations and so on. It is quite an amazing tool.
I will now write a bit about the evolution of the tool.
First, this is a code trace from the entry point of the VMProtected binary using Triton, in obfuscated form:
100a63e2 [001] push 0x8beef346
100a63e7 [002] push dword ptr [esp]
100a63ea [003] mov dword ptr [esp + 4], 0x6fdd8840
100a63f2 [004] mov byte ptr [esp], dh
100a63f5 [005] pushal
100a63f6 [006] pushal
100a63f7 [007] mov dword ptr [esp + 0x40], 0x2383346b
100a63ff [008] mov byte ptr [esp + 8], 0x5d
100a6404 [009] lea esp, dword ptr [esp + 0x40]
100a6408 [010] jmp 0x100c8e85
100c8e85 [011] pushal
100c8e86 [012] pushfd
100c8e87 [013] pushfd
100c8e88 [014] mov dword ptr [esp + 0x24], eax
100c8e8c [015] push eax
100c8e8d [016] pushfd
100c8e8e [017] mov dword ptr [esp + 0x28], edx
100c8e92 [018] pushfd
100c8e93 [019] mov byte ptr [esp + 4], 0x6f
100c8e98 [020] call 0x100c87bd
100c87bd [021] jmp 0x100c895e
100c895e [022] mov dword ptr [esp + 0x2c], ebp
100c8962 [023] pushfd
100c8963 [024] call 0x100c8a92
100c8a92 [025] mov dword ptr [esp + 0x30], ebx
100c8a96 [026] mov byte ptr [esp], dh
100c8a99 [027] mov byte ptr [esp], ah
100c8a9c [028] push edi
100c8a9d [029] jmp 0x100c8d55
100c8d55 [030] mov dword ptr [esp + 0x30], esi
100c8d59 [031] mov byte ptr [esp + 4], ch
100c8d5d [032] mov dword ptr [esp + 0x2c], edi
100c8d61 [033] mov word ptr [esp], 0x79d1
100c8d67 [034] mov byte ptr [esp], cl
100c8d6a [035] mov dword ptr [esp + 0x28], ebx
100c8d6e [036] push ebx
100c8d6f [037] push ecx
100c8d70 [038] push edi
100c8d71 [039] lea esp, dword ptr [esp + 0x34]
100c8d75 [040] jmp 0x100c8c80
100c8c80 [041] bswap si
100c8c83 [042] not si
100c8c86 [043] pushal
100c8c87 [044] pushfd
100c8c89 [045] pop dword ptr [esp + 0x1c]
100c8c8d [046] shld si, di, cl
100c8c91 [047] jmp 0x100c7dbd
100c7dbd [048] mov dword ptr [esp + 0x18], ecx
100c7dc1 [049] bsf di, si
100c7dc5 [050] push dword ptr [0x100c6d15]
100c7dcb [051] pop dword ptr [esp + 0x14]
100c7dcf [052] movzx cx, bl
100c7dd3 [053] xadd edi, ebp
100c7dd6 [054] mov dword ptr [esp + 0x10], 0
100c7dde [055] cmc
100c7ddf [056] jmp 0x100c7c7b
100c7c7b [057] mov esi, dword ptr [esp + 0x40]
100c7c7f [058] bts di, ax
100c7c83 [059] btr di, 4
100c7c88 [060] add esi, 0x1644be2b
100c7c8e [061] neg di
100c7c91 [062] pushal
100c7c92 [063] clc
100c7c93 [064] xor esi, 0x69d1f651
100c7c99 [065] mov word ptr [esp], 0xfaa6
100c7c9f [066] or edi, eax
100c7ca1 [067] xchg di, bp
100c7ca4 [068] not esi
100c7ca6 [069] and bp, 0x4b2b
100c7cab [070] rcr bl, cl
100c7cad [071] dec bp
100c7cb0 [072] stc
100c7cb1 [073] lea ebp, dword ptr [esp + 0x30]
100c7cb5 [074] bts bx, bp
100c7cb9 [075] rcl bx, 4
100c7cbd [076] add di, di
100c7cc0 [077] neg bx
100c7cc3 [078] sub esp, 0x90
100c7cc9 [079] push esp
100c7cca [080] lea edi, dword ptr [esp + 4]
100c7cce [081] lea esp, dword ptr [esp + 4]
100c7cd2 [082] adc bl, dl
100c7cd4 [083] mov ebx, esi
100c7cd6 [084] dec al
100c7cd8 [085] xor cl, cl
100c7cda [086] cmc
100c7cdb [087] cmp esi, 0xae51dbba
100c7ce1 [088] add esi, dword ptr [ebp]
100c7ce4 [089] clc
100c7ce5 [090] not cl
100c7ce7 [091] mov al, byte ptr [esi]
100c7ce9 [092] shr cl, 3
100c7cec [093] rol cl, 6
100c7cef [094] add al, bl
100c7cf1 [095] movsx cx, dl
100c7cf5 [096] rcl ch, 2
100c7cf8 [097] movzx cx, al
100c7cfc [098] pushal
100c7cfd [099] rol al, 7
100c7d00 [100] or ch, dl
100c7d02 [101] shrd cx, di, 6
100c7d07 [102] shl cl, cl
100c7d09 [103] pushal
100c7d0a [104] neg al
100c7d0c [105] mov cl, 0x47
100c7d0e [106] call 0x100c6d19
100c6d19 [107] clc
100c6d1a [108] sub esi, -1
100c6d1d [109] test dh, 0x18
100c6d20 [110] not al
100c6d22 [111] dec ecx
100c6d23 [112] add bl, al
100c6d25 [113] rcl cx, 3
100c6d29 [114] rcr ch, 7
100c6d2c [115] rcr ch, 2
100c6d2f [116] movzx eax, al
100c6d32 [117] mov byte ptr [esp], bl
100c6d35 [118] clc
100c6d36 [119] not cl
100c6d38 [120] mov ecx, dword ptr [eax*4 + 0x100c7e65]
100c6d3f [121] lea esp, dword ptr [esp + 0x44]
100c6d43 [122] jb 0x100c8390
100c6d49 [123] push 0x968f74f5
100c6d4e [124] push dword ptr [esp]
100c6d51 [125] ror ecx, 0xc
100c6d54 [126] test bx, ax
100c6d57 [127] add ecx, 0
100c6d5d [128] mov byte ptr [esp + 4], bl
100c6d61 [129] mov dword ptr [esp + 4], ecx
100c6d65 [130] pushal
100c6d66 [131] push esp
100c6d67 [132] push dword ptr [esp + 0x28]
100c6d6b [133] ret 0x2c
And this is the deobfuscated code from my tool at the beginning:
[003] mov dword ptr [esp + 4], 0x6fdd8840
[007] mov dword ptr [esp + 0x40], 0x2383346b
[014] mov dword ptr [esp + 0x24], eax
[017] mov dword ptr [esp + 0x28], edx
[022] mov dword ptr [esp + 0x2c], ebp
[025] mov dword ptr [esp + 0x30], ebx
[030] mov dword ptr [esp + 0x30], esi
[032] mov dword ptr [esp + 0x2c], edi
[035] mov dword ptr [esp + 0x28], ebx
[041] bswap si
[042] not si
[043] pushal
[044] pushfd
[045] pop dword ptr [esp + 0x1c]
[046] shld si, di, cl
[048] mov dword ptr [esp + 0x18], ecx
[049] bsf di, si
[050] push dword ptr [0x100c6d15]
[051] pop dword ptr [esp + 0x14]
[052] movzx cx, bl
[053] xadd edi, ebp
[054] mov dword ptr [esp + 0x10], 0
[057] mov esi, dword ptr [esp + 0x40]
[058] bts di, ax
[059] btr di, 4
[060] add esi, 0x1644be2b
[061] neg di
[062] pushal
[064] xor esi, 0x69d1f651
[065] mov word ptr [esp], 0xfaa6
[068] not esi
[073] lea ebp, dword ptr [esp + 0x30]
[080] lea edi, dword ptr [esp + 4]
[083] mov ebx, esi
[088] add esi, dword ptr [ebp]
[091] mov al, byte ptr [esi]
[094] add al, bl
[099] rol al, 7
[104] neg al
[108] sub esi, -1
[110] not al
[112] add bl, al
[116] movzx eax, al
[120] mov ecx, dword ptr [eax*4 + 0x100c7e65]
[125] ror ecx, 0xc
[127] add ecx, 0
[129] mov dword ptr [esp + 4], ecx
[132] push dword ptr [esp + 0x28]
[133] ret 0x2c
The obfuscated code was 133 instructions, the deobfuscated form (which looks much more readable) is 49 instructions.
If you actually try to read the code you will find it problematic when it comes to stack accesses. As described above, I do not track esp so instructions that just modify esp like:
sub esp, 0x40
are not in there. Therefore the code is unreadable as we never know what stack location is accessed. I thought about how to solve this and chose the following approach.
Thanks to Triton I know what actual stack location each access is going to. So I just give each unique address a name. This gives us the following:
[003] mov dword ptr [svar0], 0x6fdd8840
[007] mov dword ptr [svar1], 0x2383346b
[014] mov dword ptr [svar2], eax
[017] mov dword ptr [svar3], edx
[022] mov dword ptr [svar4], ebp
[025] mov dword ptr [svar5], ebx
[030] mov dword ptr [svar6], esi
[032] mov dword ptr [svar7], edi
[035] mov dword ptr [svar8], ebx
[041] bswap si
[042] not si
[043] pushal
[044] pushfd
[045] pop dword ptr [svar9]
[046] shld si, di, cl
[048] mov dword ptr [svar10], ecx
[049] bsf di, si
[050] push dword ptr [0x100c6d15]
[051] pop dword ptr [svar11]
[052] movzx cx, bl
[053] xadd edi, ebp
[054] mov dword ptr [svar12], 0
[057] mov esi, dword ptr [svar0]
[058] bts di, ax
[059] btr di, 4
[060] add esi, 0x1644be2b
[061] neg di
[062] pushal
[064] xor esi, 0x69d1f651
[065] mov word ptr [svar13], 0xfaa6
[068] not esi
[073] lea ebp, dword ptr [svar12]
[080] lea edi, dword ptr [svar14]
[083] mov ebx, esi
[088] add esi, dword ptr [ebp]
[091] mov al, byte ptr [esi]
[094] add al, bl
[099] rol al, 7
[104] neg al
[108] sub esi, -1
[110] not al
[112] add bl, al
[116] movzx eax, al
[120] mov ecx, dword ptr [eax*4 + 0x100c7e65]
[125] ror ecx, 0xc
[127] add ecx, 0
[129] mov dword ptr [svar15], ecx
[132] push dword ptr [svar15]
[133] ret 0x2c
We now can easily read the code and stack accesses are obvious too.
I was also required to add some workarounds because Triton does not implement x86 semantics cleanly. I've opened an issue on github for it. For example the rol instruction does not read the carry flag but due to the implementation (it reads the old value to write it back if the rol is a special edge case) Triton would actually say rol reads the carry flag leading to instruction dependencies that just aren't there.
Proof
The deobfuscated code above looks nice and all, but I have yet to prove the result is worth anything. After all I just might have discarded important instructions.
So as a proof I will use the above code and calculate the jump location at the end. I've annotated the disassembly:
[003] mov dword ptr [svar0], 0x6fdd8840
[007] mov dword ptr [svar1], 0x2383346b
[014] mov dword ptr [svar2], eax
[017] mov dword ptr [svar3], edx
[022] mov dword ptr [svar4], ebp
[025] mov dword ptr [svar5], ebx
[030] mov dword ptr [svar6], esi
[032] mov dword ptr [svar7], edi
[035] mov dword ptr [svar8], ebx
[041] bswap si
[042] not si
[043] pushal
[044] pushfd
[045] pop dword ptr [svar9]
[046] shld si, di, cl
[048] mov dword ptr [svar10], ecx
[049] bsf di, si
[050] push dword ptr [0x100c6d15]
[051] pop dword ptr [svar11]
[052] movzx cx, bl
[053] xadd edi, ebp
[054] mov dword ptr [svar12], 0 svar12 = 0
[057] mov esi, dword ptr [svar0] esi = 0x6fdd8840
[058] bts di, ax
[059] btr di, 4
[060] add esi, 0x1644be2b esi = 0x8622466B
[061] neg di
[062] pushal
[064] xor esi, 0x69d1f651 esi = 0xEFF3B03A
[065] mov word ptr [svar13], 0xfaa6
[068] not esi esi = 100C4FC5
[073] lea ebp, dword ptr [svar12] ebp = pointer to svar12 (which is 0)
[080] lea edi, dword ptr [svar14]
[083] mov ebx, esi ebx = 100C4FC5
[088] add esi, dword ptr [ebp] esi = 100C4FC5
[091] mov al, byte ptr [esi] al = 0x41 (lookup done in IDA)
[094] add al, bl al = 0x06
[099] rol al, 7 al = 3
[104] neg al al = 0xFD
[108] sub esi, -1 esi = 100C4FC6
[110] not al al = 2
[112] add bl, al
[116] movzx eax, al eax = 2
[120] mov ecx, dword ptr [eax*4 + 0x100c7e65] ecx = 0xc8bd0100 (lookup done in IDA)
[125] ror ecx, 0xc ecx = 100c8bd0
[127] add ecx, 0
[129] mov dword ptr [svar15], ecx
[132] push dword ptr [svar15]
[133] ret 0x2c jmp 100c8bd0
And to confirm that result, here's the target in OllyDbg:
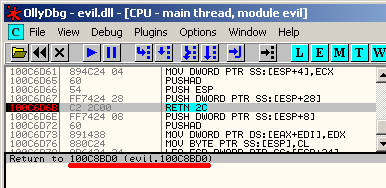
So the deobfuscated code actually seems to be good enough for that. This doesn't prove it didn't discard any important instructions but the result is usable.
Future work
I quickly noticed my stack var system is fine but when you move on to the next code blob obviously none of the names help anymore. So to actually make the tool practical I may need to see how to handle the stack issue globally.
As mentioned above, register aliasing is on the TODO list, as is just a general code cleanup, it's really not pretty. Memory writes aren't considered relevant yet, which I need to add in, too.
And obviously the code only works for x86 for now but porting it to x64 should be easy.
I'm quite happy with the result for now. Thank you for reading so far!
Links
You can find the script on my github
If you want to see the unadorned raw output, see output.txt